A data scientist has written a feature engineering notebook that utilizes the pandas library. As the size of the data processed by the notebook increases, the notebook's runtime is drastically increasing, but it is processing slowly as the size of the data included in the process increases.
Which of the following tools can the data scientist use to spend the least amount of time refactoring their notebook to scale with big data?
A machine learning engineering team has a Job with three successive tasks. Each task runs a single notebook. The team has been alerted that the Job has failed in its latest run.
Which of the following approaches can the team use to identify which task is the cause of the failure?
A data scientist has been given an incomplete notebook from the data engineering team. The notebook uses a Spark DataFrame spark_df on which the data scientist needs to perform further feature engineering. Unfortunately, the data scientist has not yet learned the PySpark DataFrame API.
Which of the following blocks of code can the data scientist run to be able to use the pandas API on Spark?
A data scientist is wanting to explore summary statistics for Spark DataFrame spark_df. The data scientist wants to see the count, mean, standard deviation, minimum, maximum, and interquartile range (IQR) for each numerical feature.
Which of the following lines of code can the data scientist run to accomplish the task?
A data scientist wants to parallelize the training of trees in a gradient boosted tree to speed up the training process. A colleague suggests that parallelizing a boosted tree algorithm can be difficult.
Which of the following describes why?
A data scientist has created two linear regression models. The first model uses price as a label variable and the second model uses log(price) as a label variable. When evaluating the RMSE of each model bycomparing the label predictions to the actual price values, the data scientist notices that the RMSE for the second model is much larger than the RMSE of the first model.
Which of the following possible explanations for this difference is invalid?
Which of the following tools can be used to parallelize the hyperparameter tuning process for single-node machine learning models using a Spark cluster?
A health organization is developing a classification model to determine whether or not a patient currently has a specific type of infection. The organization's leaders want to maximize the number of positive cases identified by the model.
Which of the following classification metrics should be used to evaluate the model?
Which of the following approaches can be used to view the notebook that was run to create an MLflow run?
A data scientist has developed a linear regression model using Spark ML and computed the predictions in a Spark DataFrame preds_df with the following schema:
prediction DOUBLE
actual DOUBLE
Which of the following code blocks can be used to compute the root mean-squared-error of the model according to the data in preds_df and assign it to the rmse variable?
A)

B)

C)

D)

E)

A data scientist has created a linear regression model that useslog(price)as a label variable. Using this model, they have performed inference and the predictions and actual label values are in Spark DataFramepreds_df.
They are using the following code block to evaluate the model:
regression_evaluator.setMetricName("rmse").evaluate(preds_df)
Which of the following changes should the data scientist make to evaluate the RMSE in a way that is comparable withprice?
A machine learning engineer has created a Feature Table new_table using Feature Store Client fs. When creating the table, they specified a metadata description with key information about the Feature Table. They now want to retrieve that metadata programmatically.
Which of the following lines of code will return the metadata description?
Which of the following evaluation metrics is not suitable to evaluate runs in AutoML experiments for regression problems?
A data scientist wants to use Spark ML to one-hot encode the categorical features in their PySpark DataFramefeatures_df. A list of the names of the string columns is assigned to theinput_columnsvariable.
They have developed this code block to accomplish this task:
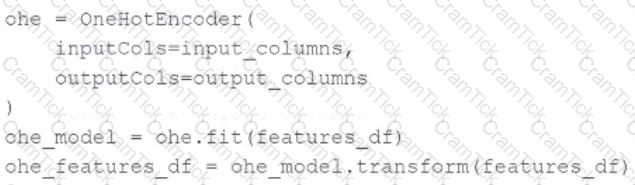
The code block is returning an error.
Which of the following adjustments does the data scientist need to make to accomplish this task?
A data scientist has developed a linear regression model using Spark ML and computed the predictions in a Spark DataFrame preds_df with the following schema:
prediction DOUBLE
actual DOUBLE
Which of the following code blocks can be used to compute the root mean-squared-error of the model according to the data in preds_df and assign it to the rmse variable?
A)

B)

C)

D)

What is the name of the method that transforms categorical features into a series of binary indicator feature variables?




TESTED 13 Mar 2026