What is a drawback to performing data cleansing (imputation, transformations, etc.) on raw data prior to partitioning the data for honest assessment as opposed to performing the data cleansing after partitioning the data?
Refer to the exhibit:
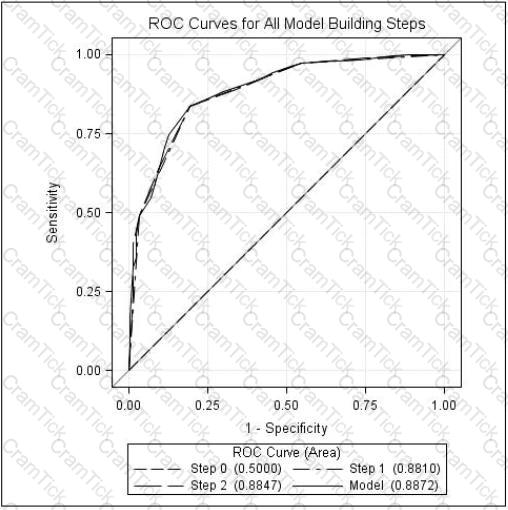
An analyst examined logistic regression models for predicting whether a customer would make a purchase. The ROC curve displayed summarizes the models. Using the selected model and the analyst's decision rule, 25% of the customers who did not make a purchase are incorrectly classified as purchasers.
What can be concluded from the graph?
A financial services manager wants to assess the probability that certain clients will default on their Home Equity Line of Credit (HELOC). A former employee left the code listed below.

The training data set is named HELOC, while a similar data set of more recent clients is named RECENT_HELOC.
Which SAS data steps will calculate the predicted probability of default on recent clients? (Choose two.)

A confusion matrix is created for data that were oversampled due to a rare target.
What values are not affected by this oversampling?
The total modeling data has been split into training, validation, and test data.
What is the best data to use for model assessment?
Given the following output from the LOGISTIC procedure:

Which variables, among those that are statistically significant at an alpha of 0.05, have the greatest and least relative importance on the fitted model?
When mean imputation is performed on data after the data is partitioned for honest assessment, what is the most appropriate method for handling the mean imputation?
Refer to the exhibit.

Output from a multiple linear regression analysis is shown.
What is the most appropriate statement concerning collinearity between the input variables?
A non-contributing predictor variable (Pr > |t| =0.658) is added to an existing multiple linear regression model.
What will be the result?
This question will ask you to provide a segment of missing code.
The following code is used to create missing value indicator variables for input variables, fred1 to fred7.

Which segment of code would complete the task?

Which SAS program will divide the original data set into 60% training and 40% validation data sets, stratified by county?

Statistical Business Analyst | A00-240 Questions Answers | A00-240 Test Prep | SAS Statistical Business Analysis SAS9: Regression and Model Questions PDF | A00-240 Online Exam | A00-240 Practice Test | A00-240 PDF | A00-240 Test Questions | A00-240 Study Material | A00-240 Exam Preparation | A00-240 Valid Dumps | A00-240 Real Questions | Statistical Business Analyst A00-240 Exam Questions




TESTED 27 Mar 2026